





When storing web pages, documents, locations, images, media and other data on websites, vector databases give us new tools for revolutionising how we store and interact with such data.
In this article I'm considering natural language content, such as web pages and documents that are stored on websites
How can websites do a better job with such content by using the features of vector databases?
A little background
You may have heard of relational databases; these have been the mainstay of much online data for over 25 years. In small and medium sized applications such as website content management systems, these have been the principal way that content is stored.
In a relational database, there are tables, each of which consists of rows and columns. At the intersection of rows and columns are fields. This is where the actual data sits.
Here is what a relational database table looks like:

The table has a fixed set of columns, which have names. For example, there is typically an "id" column (a unique number to identify that row specifically, called a primary key), and there are columns for other things, for example "document name" or "date modified".
When data is added, it creates a row, or record, in the table. It's rather like a spreadsheet.
The power of a relational database emerges when tables are related to each other. With multi-table structures, sophisticated applications can be created. Over the years, relational databases have evolved a good deal, to be extremely fast, scalable, and robust.
One weakness of a relational database is that holes can occur; for a given row, a field may be empty. That is not a big problem, but a lot of empty fields is less than optimal for efficiency.
Similarly, it is not easy for additional columns to be added. If there's some data that the application needs to add just once in a while, it cannot spontaneously add that data, because a column would first need to be created for it, and that is a change that needs more consideration. So a relational database is a rather well-organised, formal way of storing data, and not flexible or organic enough to easily handle changing needs.
Vector databases
In contrast with relational databases, a vector database takes a different approach. Instead of tables there are collections; and instead of rows there are points.
Here's a conceptual view of a collection in a vector database:
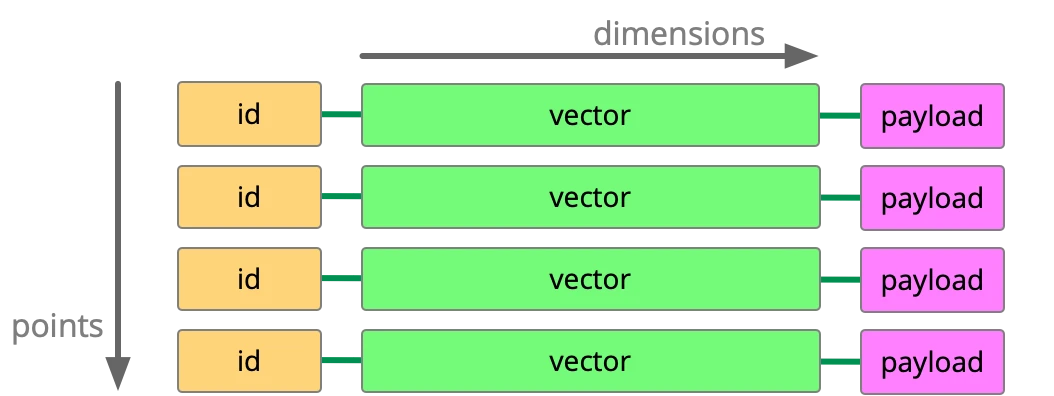
(This is how a collection looks in the Qdrant vector database system, which we've been working with a good deal, but other vector databases may be different.)
A collection contains points, and each point contains a unique numeric ID, a multi-dimensional vector, and a payload.
Let's assume we have a collection for storing textual data from a library of PDF documents. Each point will correspond with a block of data from a document, and its vector will be a numeric representation of that block of data.
The vector can be visualised as an array with a set of numbers in sequence. Within a given collection, every vector will have the same number of numbers. The number of numbers in each vector is called the dimensionality; so for example, if each vector consists of four numbers, it would be said that the dimensionality will be four.
There is a payload for each point. This contains familiar looking data, as it may contain the original text, plus IDs, meta data, the language of the original text, and other information about the point.
Vectors and encoding
When creating the point in the vector database, the original natural language text is put through an encoder in order to convert it to vector form. You can envisage the process of encoding a text document like this:
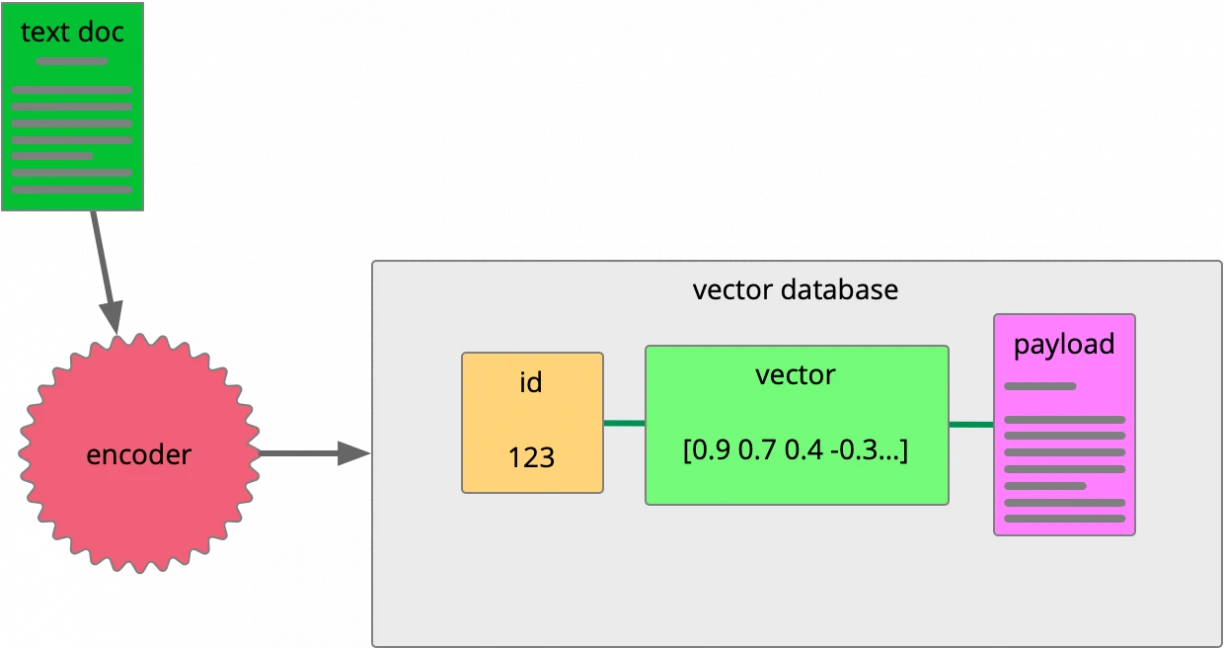
An encoder scans the text document; it first simplifies it, and then encodes it.
Simplification of the source text means removing stop-words (like "the" or "with"). It also entails lemmatising words, which means grouping together similar forms of the same word, like "whale" or "whales", which could be considered the same thing for matching purposes. This reduces the overall size and complexity of the data, and allows a lower dimensionality vector to be used. Storage size is reduced, and performance improved.
Encoders cover many different purposes. They have been pre-trained for a particular purpose, and the right encoder needs to be chosen according to the application. An encoder may work in a specific language, or may be designed for handling images, audio, numeric data and so on. The encoder's job is to take some input data and convert it into an array of numbers, while preserving the overall meaning.
The simplified, encoded data is written into the vector, with an ID to reference it. A payload is added, which may have meta data, or other information about the point.
Envisaging the vector data
If you're with me so far, that's great. I'm quite a visual person, so I now going to do the rather hard thing of visualising the data in the vector database.
Let's imagine the text we are trying to represent is really simple, just words like "whale" or "blue whale". And let's also imagine that our vector database uses really simple 2-dimensional representations.
If we were to insert some of these simple phrases, we might envisage them in a 2-d word-space, like this:
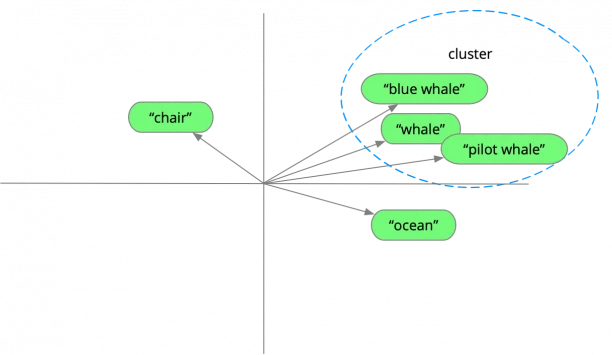
See what is happening? The similar terms like, "whale", "pilot whale" and "blue whale" are close together — they are in a cluster.
Less well related words like "ocean" and "chair" are further away.
Clusters represent vectors that are close together; they are close together because they represent similar meanings, or because they are similar in other ways, such as their spelling or sound.
Coming back to our idea of storing blocks of text, when there is a dense cluster of points close together, that will be because the original blocks had similar meaning. Where a vector is distant from other vectors, it represents blocks of text with more distinct meanings.
In a real system, the data points have much higher dimensionality — commonly with 384 dimensions, or more. When ChatGPT stores data from the internet, it uses 2,048 dimensions!
That number is impossible to visualise, but the principle is the same. I like to let my imagination fly a little, and hopefully you too can see how these systems are brilliant at modelling all kinds of information
Once the data has been stored in a vector database, what happens? Well, that depends on the application, because many things now become possible. In this article I am going to look at how storing data in vectors can help with semantic searching.
Semantic searching
When a user goes to a website and does a search, or asks a question, how can we improve the experience?
This is where semantic searching comes in. Semantic searching means searching by meaning rather than by doing a textual comparison.
Let's imagine a user searches with the term "orca". When the search term is entered, "orca" gets encoded. The application passes "orca" to the vector database in vector form, and the database compares this vector with the stored vectors.
If we could see how the vector database sees the stored data (the green words), and the search term (the pink block), it might look something like this:
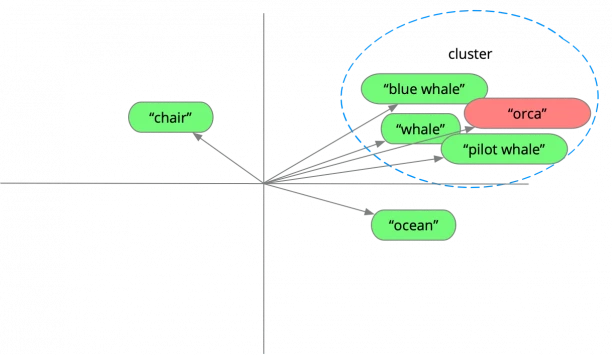
This diagram is again very much simplified, because of course the dimensionality is much higher, and really those words are numeric vectors, but hopefully you get the idea.
Notice how the search term "orca" is near the "whale" terms. It's nearby because the encoder realised that "orca" is nearly synonymous with "killer whale". So its vector appears in the word-space near the whale-related cluster, but not at all near other terms like "chair".
The vector database system's power is in being able to compare the numeric representations of the vectors rapidly.
The result of the search is a list of matching points, usually sorted with the nearest shown first. Very distant matches are omitted. The system takes care of presenting the results, so what the user sees is references to "whale" and so on, so they can review relevant nearby content.
The website application takes care of the user experience, so the user doesn't see any of this complexity. When the search result comes back from the vector database, it can present the results in a familiar way, with document title, images and other information being shown, which may come from its conventional relational database.
Other kinds of searching
There are in fact different ways of finding nearby matches — these algorithms have names like cosine similarity, and dot product. Cosine similarity is useful when text is stored, while other algorithms are good for numbers, or for image comparison.
There's not space to go into them here, but I'll just say that different algorithms are chosen according to the type of data being modelled.
Conclusion
When implemented on a real system, a vector database allows a whole new set of features to be employed on a website, extranet, or similar system. What I've covered here shows how textual documents of web pages are stored in a vector database, and how the vector database allows a user to do semantic searching on that data, which can be more powerful than searching based on text matching alone.
This just scratches the surface of what is possible, and I will write further articles on the possibilities. Check this site again soon, or drop me a message here.
Recent posts
Zenario 10.0 announced
22 Jul 2024
Re-design of website for Mortgage Required
22 Aug 2023
New site launched for Salecology
12 Jul 2023
New design for International Camellia Society
20 Jan 2023
How to migrate your Analytics to Google’s GA4
30 Sep 2022